HealthAnalyticsToolkit
COVID-19 Analysis
First, the correct libraries need to be imported. This tutorial utilizes the following libraries:
- pandas is a data analysis and manipulation tool
- NumPy is a package for the scientific computing in Python that provides a multidimensional array object, arrays, matrices, and an assortment of opperations and manipulations.
- matplotlib.pyplot provides a MATLAB-like way of plotting
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
Import the Data
The file used in this tutorial can be found here. The information is regularly updated so if you get slighly different numerical results, do not be concerned. Data is stored in a csv file. To read the data, we can use pandas.read_csv. This reads a comma-separated values (csv) file into a DataFrame.
data = pd.read_csv("state_policy_updates_20210221_0722.csv") #Read csv
data
| state_id | county | fips_code | policy_level | date | policy_type | start_stop | comments | source | total_phases | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | HI | NaN | NaN | state | 2020-05-18 | Manufacturing | start | Policy_Details: Open with adjusted "Safe Pract... | sip_submission_form: https://governor.hawaii.g... | NaN |
| 1 | TX | Kinney | 48271.0 | county | 2020-07-03 | Mask Requirement | start | Policy_Details: County is approved to be exemp... | sip_submission_form: https://tdem.texas.gov/ga... | NaN |
| 2 | ID | Custer | 16037.0 | county | 2020-10-27 | Phase 3 | start | Policy_Details: No greater than 50 people at i... | sip_submission_form: https://coronavirus.idaho... | 4.0 |
| 3 | UT | Wayne | 49055.0 | county | 2020-11-24 | Phase 1 | start | Policy_Details: Restrictions for highest level... | sip_submission_form: https://coronavirus.utah.... | 3.0 |
| 4 | IL | Ford | 17053.0 | county | 2021-01-15 | Food and Drink | start | Policy_Details: Bars and restaurants: Open wit... | sip_submission_form: https://coronavirus.illin... | 5.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4175 | TX | Morris | 48343.0 | county | 2020-07-03 | Mask Requirement | start | Policy_Details: County is approved to be exemp... | sip_submission_form: https://tdem.texas.gov/ga... | NaN |
| 4176 | ME | Piscataquis | 23021.0 | county | 2020-05-18 | Outdoor and Recreation | start | Policy_Details: Rural Reopening : wilderness ... | sip_submission_form: https://www.maine.gov/cov... | 3.0 |
| 4177 | NY | NaN | NaN | state | 0020-06-08 | Resumed Elective Medical Procedures | start | Other measures and details for this policy inc... | BU COVID-19 State Policy Database | NaN |
| 4178 | WV | NaN | NaN | state | 2020-03-19 | Food and Drink | start | Other measures and details for this policy inc... | BU COVID-19 State Policy Database | NaN |
| 4179 | IL | Lee | 17103.0 | county | 2021-01-15 | Non-Essential Businesses | start | Policy_Details: - All employees return to work... | sip_submission_form: https://coronavirus.illin... | 5.0 |
4180 rows × 10 columns
Clean the Data
After reading the data in, we want to clean the data. In this dataset, some of the dates state 0020 instead of 2020 for the year. Additionally, one data point has 1899 as the date. Being that COVID is more recent, that year is assumed to be 2020 as well. The following code locates and fixes the errors in the dates in the data set.
dates_to_change = []
for index, row in data.iterrows():
if "0020" == row.date[0:4]:
data.loc[index, "date"] = "2020" + row.date[4:]
elif "1899" == row.date[0:4]:
data.loc[index, "date"] = "2020" + row.date[4:]
Th above for loop iterates through each row in the DataFrame stored in data. With each row, the if/elsif statements check to see if the first four digits of the date are either “0020” or “1899” with the equal-to operator (==). If either of the error values are present, the values are replaced with “2020”.
Analysis
Initial Investigation of Policies
To begin the investigation, let us visualize the data in a scatter plot. The below code does just that in the following steps:
- Sort the values by the “state_id” column.
- Using a mask, find and store all the rows that are labeled as “start” in the “start_stop” column in a variable called “start_scat”
- Create a scatter plot with the data in “start_scat”. Put the values from the “date” column on the x-axis and “policy_type” on the y-axis. The color of the dot on the scatter plot will be assigned by the “state_id”, meaning that each of the dots associated with a given state will be the same color. .
sorted = data.sort_values(by=["state_id"]) #sort the data by state
start_scat = sorted[(sorted.start_stop=="start")]
px.scatter(start_scat, x="date",y= "policy_type", color = "state_id", title = "Policies by State and Date")
The initial scatterplot provides a crude visualization of how start of policies in timeseries, color-coded by state. There is not much one can tell from this graph aside from the fact that the implementation of any given policy varied widely in time.
Investigating the Number of Times Each Policy Starts
The code below finds the three most started policies, by counting the number of times that policy was started. This means if that policy was started mulitple times in a single state, it would be counted each time.
start_data = data[(data.start_stop=="start")] #Look only at the start of policies
policies = start_data.policy_type.unique() #Find all the unique policies
count = [] #Create an empty count vector
for val in start_data.policy_type.unique(): #Create a for loop to go through each unique policy
ope = start_data[start_data.policy_type == val] #using a mask, find all the policies that match the unique policy
siz = ope.shape #find out the number of rows that have that policy
count.append(siz[0])
d = {"policy":policies, "num_starts":count}
results = pd.DataFrame(d) #create results dataframe
results.sort_values(by=["num_starts"], ascending = False) #sort the data from largest to smallest number of starts
| policy | num_starts | |
|---|---|---|
| 10 | Shelter in Place | 462 |
| 4 | Food and Drink | 263 |
| 16 | Outdoor and Recreation | 242 |
| 1 | Mask Requirement | 239 |
| 13 | Non-Essential Businesses | 226 |
| ... | ... | ... |
| 44 | Medical | 1 |
| 38 | Colleges & Universities | 1 |
| 42 | Graduation Ceremony guidelines | 1 |
| 41 | State of Emergency/Funds | 1 |
| 64 | Agriculture | 1 |
65 rows × 2 columns
By printing the dataframe, one can see the policies with the most starts include: Shelter in Place with 462 starts, Food and Drink with 263 starts, and Outdoor and Recreation with 242 starts.
Investigating the Widespread Use of Policies
The code below looks the number of states/territories that implemented each policy. This is interesting to see how widespread the implementation of certain policies are and to determine their reach across the nation.
count = [] #reset count to 0
for val in start_data.policy_type.unique(): #loop through each unique policy
poli = start_data[start_data.policy_type == val] # poli hold the dataframe rows for the unique policy
ct = 0 #set a counter variable to 0
for val2 in poli.state_id.unique(): #loop through each unique state within poli
ct = ct + 1 #increment count for each unique state
count.append(ct) #Add the number of states to the counter list
results["num_states"] = count #Add to the results dataframe
results.sort_values(by=["num_states"], ascending = False) #sort the data by state
| policy | num_starts | num_states | |
|---|---|---|---|
| 13 | Non-Essential Businesses | 226 | 54 |
| 4 | Food and Drink | 263 | 54 |
| 12 | Entertainment | 196 | 53 |
| 5 | Childcare (K-12) | 193 | 53 |
| 16 | Outdoor and Recreation | 242 | 52 |
| ... | ... | ... | ... |
| 38 | Colleges & Universities | 1 | 1 |
| 36 | Graduation | 1 | 1 |
| 11 | Wholesale Trade | 5 | 1 |
| 27 | Public Health Advisory System | 27 | 1 |
| 64 | Agriculture | 1 | 1 |
65 rows × 3 columns
The policies with the most widespread implementation include: Non-Essential Businesses with 54 states/territories starting that policy, Food and Drink with 54 states/territories starting that policy, Entertainment with 53 states/territories starting that policy, and Childcare (K-12) with 53 states/terrirtories starting that policy.
Visualization of Policy Implementation Across the US
sorted_by_state = results.sort_values(by=["num_states"], ascending = False) #sort the data by state
plt.figure(figsize=(25, 5))
plt.bar(sorted_by_state.policy,sorted_by_state.num_states)
plt.xticks(rotation = 'vertical')
plt.ylabel('Number of States Starting Policy')
plt.xlabel('Policy')
plt.title("Policy Implementation Across US: Number of States Starting Policy vs Policy")
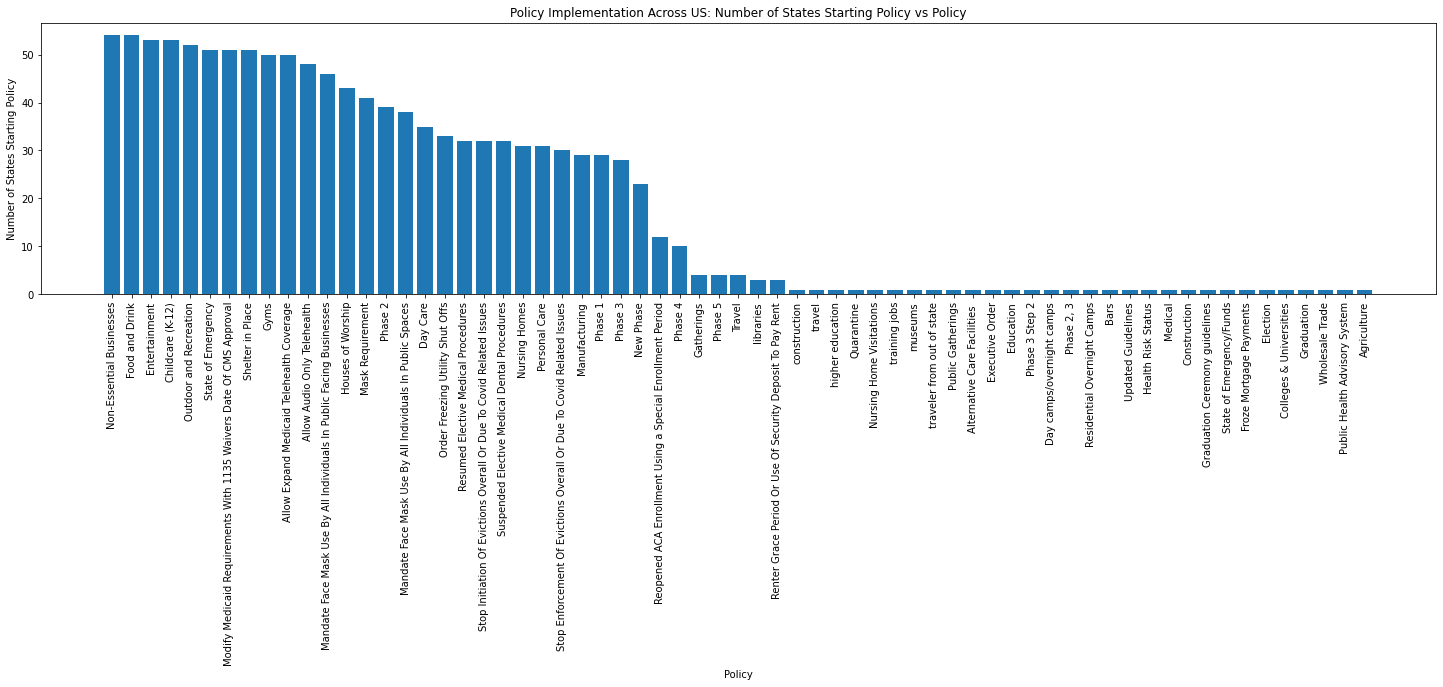
What about Mask Requirements?
In as early as April, the CDC recommended masks to prevent the spread of the virus. However, interestingly, masks requirements do not make the top of the list for the number or starts or for being a widespread policy across the nation. This seems to be a major gap in slowing/stopping the pandemic!
To further understand, we want to look at which policies involve masks and further investigate them.
num = 0;
for index, row in results.iterrows():
if ("Mask" in row.policy):
num = num+1
The above for loop iterates thorugh each row in the DataFrame. If the work “mask” appeared within the policy name of a given row, the counting variable “num” was increased by 1.
After completion of this loop, num equals 3. There are three different mask related policies: “Mask Requirements”, “Mandate Face Mask Use By All Individuals In Public Spaces”, and “Mandate Face Mask Use By All Individuals In Public Facing Businesses”, all of which we will look at below.
mask_req = results[results.policy == "Mask Requirement"]
mask_public = results[results.policy =="Mandate Face Mask Use By All Individuals In Public Spaces"]
mask_bus = results[results.policy =="Mandate Face Mask Use By All Individuals In Public Facing Businesses"]
mask_req
| policy | num_starts | num_states | |
|---|---|---|---|
| 1 | Mask Requirement | 239 | 41 |
mask_public
| policy | num_starts | num_states | |
|---|---|---|---|
| 14 | Mandate Face Mask Use By All Individuals In Pu... | 38 | 38 |
mask_bus
| policy | num_starts | num_states | |
|---|---|---|---|
| 24 | Mandate Face Mask Use By All Individuals In Pu... | 46 | 46 |
Mask Requirement had the highest number of starts with 239 starts and 41 different states. Mandate Face Mask Use By all Individuals in Public Facing Businesses had the next highest number, with 46 starts and 46 states. Finally, Mandate Face Mask Use By All Individuals in Public Spaces had 38 starts and 38 states.
With these numbers, the next question is: How many states implemented any of the Masks policies? The following code investigates that question.
data_copy = data.copy() #Create a copy of the data
#Loop through and change any policy type involving masks to be called Mask in the copy of the data
for index, row in data_copy.iterrows():
if ("Mask" in row.policy_type):
data_copy.loc[index, "policy_type"] = "Mask"
data_copy = data_copy[(data_copy.start_stop=="start")] #Look only at the data that is a "start"
count = [] #reset count to 0
for val in data_copy.policy_type.unique(): #loop through each unique policy
poli = data_copy[data_copy.policy_type == val] # poli hold the dataframe rows for the unique policy
ct = 0 #set a counter variable to 0
for val2 in poli.state_id.unique(): #loop through each unique state within poli
ct = ct + 1 #increment count for each unique state
count.append(ct) #Add the number of states to the counter list
policies2 = data_copy.policy_type.unique() #Find all the unique policies
w = {"policy":policies2, "num_states":count}
results_mask = pd.DataFrame(w) #create dataframe
results_mask[(results_mask.policy == "Mask")] #Look at the number of states that implemented a mask related policy
| policy | num_states | |
|---|---|---|
| 1 | Mask | 51 |
In total, 51 states/territoties implemented a mask related policy. This is more widespread than the individual policies, however, would still not be in one of the top five policies implemented accross the country. Furthermore, there is variance in what these three different mask policies mean for the public regarding face coverings.
mask_reqs_start_scat = px.scatter(data_copy[(data_copy.policy_type == "Mask")], x="date",y= "policy_type", color = "state_id", title = "Start Mask Requirement")
mask_reqs_start_scat
The states that did implement mask related policies started them at a variety of points throughout the pandemic. For example, HI started a mask related policy on Dec 30, 2020, this is well into the pandemic. AK and MN being two of the first to have the policy started, beginning them back in March when the pandemic was starting!
Hopefully this example gave you some ideas of how you can visualize and analyze datasets using Python!!